读《算法导论》–排序算法
直观感受排序算法
http://www.sorting-algorithms.com/,
所有代码参考:
https://github.com/fsxchen/Algorithms_Python
插入排序与冒泡排序
插入排序
对于插入排序法,最形象的解释就是下面这幅图片。

插入法的主要思想是:遍历一个数组,将遍历的那个数(key)放入到已经排好的数组中。
|
|
冒泡排序
冒泡排序的思想就比较简单,遍历序列,然后用这个数和后面所有的来比较,如果这个书比较小,那么就交换位置。
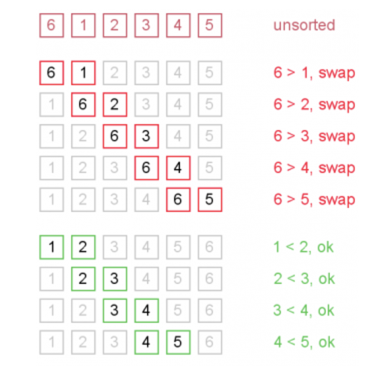
|
|
代码演示
https://github.com/fsxchen/Algorithms_Python
分析
对于这两个遍历法排序,时间复杂度都是$O(n^2)$,对于冒泡法,已经没有比较好的方法,因为不管怎样,都是需要遍历的,然后对于插入法排序,还是可以分析一下。
如果将要处理的序列是从小到大已经排好序的?
$O(n)$
如果是从大到小排好的
$O(n^2)$
堆排序
(二叉)堆是一个数组,可以近似看成一个完全二叉树。除了底层之外,其他层是完全充满的。
对于一个数组A,A.heap-size表示堆的长度,A.length表示数组长度
|
|
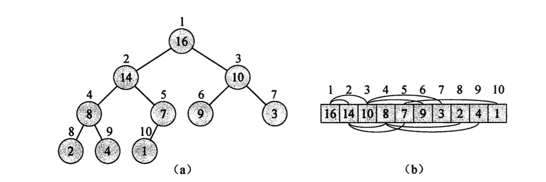
最小堆/最大堆是指A[PARRENT(i)] <=/>= A[i]
堆性质的维护
当向一个堆中加入一个数据的时候,如何维护
伪代码如下:
|
|
建堆
这里需要注意的是,如果把一个长度为n的数组转化成为一个最大堆,也就是说A.length==A.heap-size那么其叶结点的下标为n/2 + 1, ...n!,这里下标是从1开始!
|
|
考虑到这个是自底向上的建堆的方式,从低层,每次都进行一次堆最大性质的维护。那么可以保证该堆是一个最大堆。
堆排序算法
|
|
代码演示
|
|
堆的应用-优先队列
优先队列是一种用来维护由一组元素构成的集合S的数据结构,支持
- INSERT(S, x):把元素x插入到集合S中
- MAXIMUM(S):返回S中具有最大键字的元素
- EXTRACT-MAX(S):去掉并返回具有最大键字的元素
- INCREASE-KEY(S, x, k):将元素x的关键字值增加到k
如何使用堆来实现优先队列
快速排序
核心思想就是归并排序
- 分解: 数组A[p, r]将被划分为两个(可能为空)的子数组A[p..q-1]和A[q+1, r],使得A[p..q-1]中的每一个元素都小于A[q],A[q+1, r]中的每一个元素都大于A[q]
- 解决:通过递归来对子数组来排序
- 合并:不需要合并操作
|
|
关键部分在于PARTITION这个函数
|
|
快速排序的随机化版本
|
|
快速排序的优势很明显,首先在时间上,其时间复杂度为$nlgn$,其次,不会占用额外的空间,属于原址排序,节省空间,是一种运用最广泛的排序算法。
线性时间排序
任何比较排序法所用的时间最短为$nlgn$
基数排序
只应用与卡片打孔的机器
桶排序
中位数和顺序统计量
最小值和最大值
|
|
当想要获取一个序列中的一个最大值或者是最小值的时候,可以看到时间复杂度为$n$
同时找到最大值和最小值
理论上来讲,最大值需要一次比较,最小值需要一次,一共需$2(n-1)$比较。如果在每个元素之间比较,然后小值和最小值比较,大的和最大值比较,只需要比较3*n/2次
找到第i小/大的元素
|
|

